
- Слайсы / Срезы
- Обозначение элементов списка
- Пример 2
- Пример 3
- Пример 4
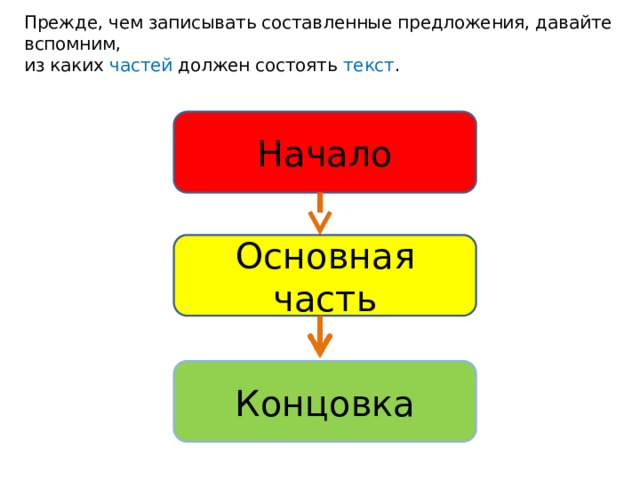
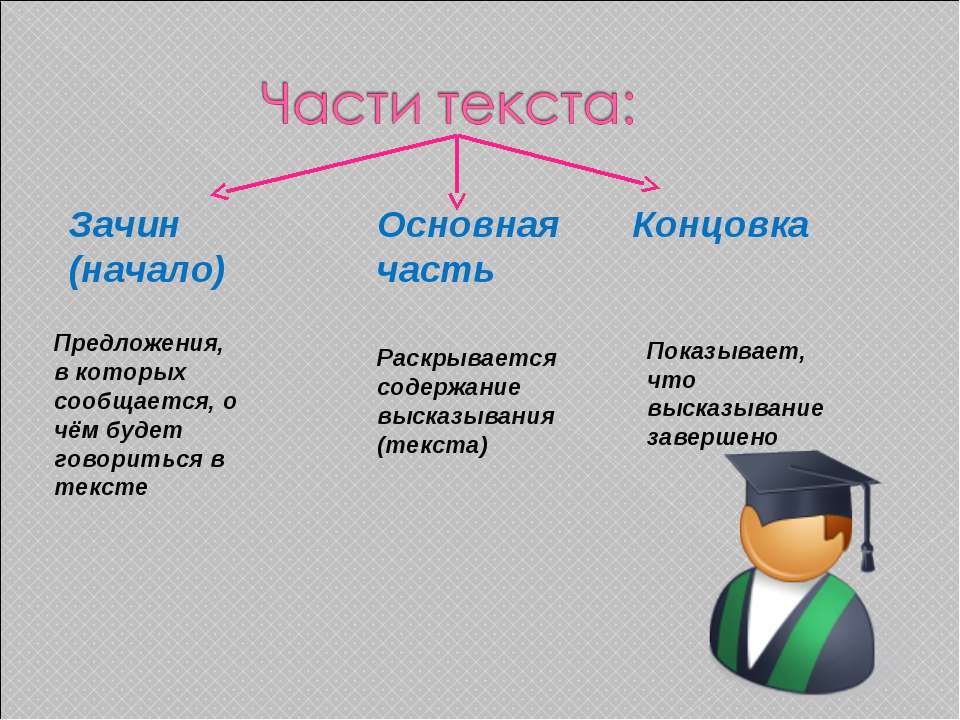
- Тема текста
- Что такое грамматическая основа предложения: определение
- По составу грамматической основы
- По числу грамматических основ
- По наличию второстепенных членов
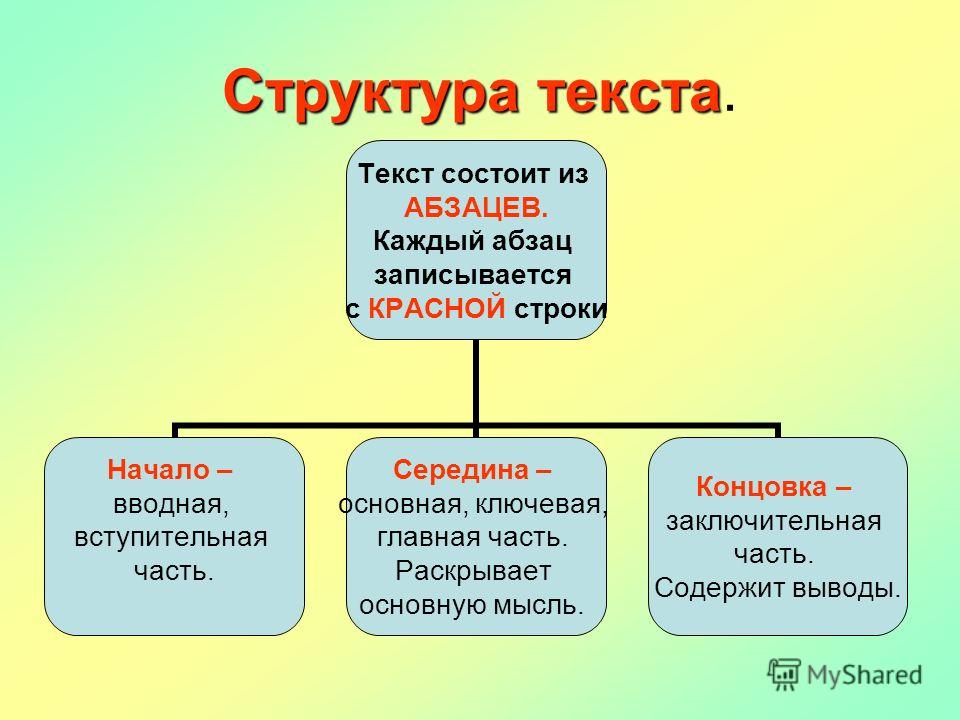
- Стили текста
- Пунктуационное оформление перечней
- Пример 5
- Пример 7
- Пример 8
- Порядок определения грамматической основы
- Определение основы в односоставных предложениях
- Двусоставные предложения: алгоритм определения грамматической основы
- Сложные случаи в определении сказуемых
- Цифры и ноты
- Сколько всего существует иероглифов?
- § 8. Создание списков в HTML
- Обозначение элементов списка
- Пример 2
- Пример 3
- Пример 4
- Как запомнить чтение иероглифов
- Обзор стилей речи, как определить стиль текста
- Как определить размер стихотворения
- Метод 1. Скандирование
- Метод 2. «Ваня»
- Метод 3. Графический
- List Comprehensions как обработчик списков
- § 9. Заключение
Слайсы / Срезы
Слайсы (срезы) являются очень мощной составляющей Python, которая позволяет быстро и лаконично решать задачи выборки элементов из списка. Выше уже был пример использования слайсов, здесь разберем более подробно работу с ними. Создадим список для экспериментов:
>>> a =
Слайс задается тройкой чисел, разделенных запятой: start:stop:step. Start – позиция с которой нужно начать выборку, stop – конечная позиция, step – шаг. При этом необходимо помнить, что выборка не включает элемент определяемый stop.
Рассмотрим примеры:
>>> # Получить копию списка >>> a >>> # Получить первые пять элементов списка >>> a >>> # Получить элементы с 3-го по 7-ой >>> a >>> # Взять из списка элементы с шагом 2 >>> a >>> # Взять из списка элементы со 2-го по 8-ой с шагом 2 >>> a
Слайсы можно сконструировать заранее, а потом уже использовать по мере необходимости. Это возможно сделать, в виду того, что слайс – это объект класса slice. Ниже приведен пример, демонстрирующий эту функциональность:
>>> s = slice(0, 5, 1) >>> a >>> s = slice(1, 8, 2) >>> a
Обозначение элементов списка
Предваряющее перечень предложение и элементы последующего списка (перечисляются после двоеточия) могут писаться в виде единой строки. Но в длинных и сложных списках гораздо удобнее располагать каждый элемент с новой строки. И тут у вас есть выбор: вы можете ограничиться использованием абзацного отступа (Пример 1) или же заменить его на цифру, букву или тире (Пример 2).
Пример 2
![]()
Перечни бывают:
-
простые, т.е. состоящие из одного уровня членения текста (см. Примеры 1 и 2) и
-
составные, включающие 2 и более уровней (см. Пример 3).
От глубины членения зависит выбор символов, которые будут предварять каждый элемент списка. При оформлении простых перечней можно использовать строчные («маленькие») буквы, арабские цифры или тире.
Гораздо сложнее обстоит дело с составными перечнями. Для большей наглядности сочетания различных символов в списках приведем пример оформления 4-уровневого перечня:
Пример 3
![]()
Из данного примера видно, что система нумерации рубрик выглядит следующим образом: заголовок первого уровня оформлен при помощи римской цифры, заголовки второго уровня – при помощи арабских цифр без скобок, заголовки третьего уровня – при помощи арабских цифр со скобками и, наконец, заголовки четвертого уровня оформлены с применением строчных букв со скобками. Если бы данный перечень предполагал еще один, пятый уровень, то его мы оформили бы при помощи тире.
Система нумерации частей составного перечня может состоять только из арабских цифр с точками.Тогда структура построения номера каждого элемента списка отражает его подчиненность по отношению к расположенным выше элементам (происходит наращивание цифровых показателей):
Пример 4
![]()
Если в конце списка стоит «и др.», «и т.д.» или «и т.п.», то такой текст не располагают на отдельной строке, а оставляют в конце предыдущего элемента списка (см. Примеры 3 и 4).
Тема текста
Дорогой друг! Теперь мы точно знаем, как отличить текст от набора предложений. Но у Непоседкина остались вопросы. Продолжим вместе с ним урок развития речи.
Давайте разбираться вместе, для этого нужно внимательно читать текст.
|
1. Внеклассное чтение – это когда ребята читают не только школьные произведения, но и другие книги. Так происходит развитие речи у детей. Благодаря чтению мы узнаем много новых слов, учимся красиво говорить. Это помогает нам строить публичные выступления. |
2. Мне нравится рисовать. Поэтому самый любимый предмет в школе — урок рисования. Я накопила коллекцию разных рисунков. Ими очень гордится моя мамочка. |
Ответьте на вопросы.
1. О чем говорится в каждом тексте?
(Ответ: 1. о чтении; 2. о рисовании.)
2. Как вы догадались, какая тема является главной?
(Ответ: по ключевым словам.)
Тема – все то, что описывается, о чем говорится в тексте.
В простых текстах тему можно увидеть в названии. В художественных произведениях тема в заглавии отображается реже.
Задание: определите тему текста.
На лугу растут травы и цветы. Изредка встречаются тоненькие березки, кустарники. Посередине поляны стоит могучий дуб. В середине лета на лугу особенно хорошо. Душистые травы, согретые солнышком, радуют взор.
Ответ: луг.
Молодцы! Вот и Непоседкину стало все понятно. Как? У него остались вопросы!?
Мы обязательно ответим любознательным ученикам!
Что такое грамматическая основа предложения: определение
Грамматическая основа предложения — это смысловой центр, основная часть предложения, которая состоит из его главных членов: подлежащего и сказуемого. В двусоставных предложениях включает в себя оба главных члена, в односоставных — один главный член.
![]()
В большинстве случаев грамматическая основа самостоятельна: если исключить все второстепенные члены, суть предложения все равно будет понятна.
Запоминаем!
Нельзя ставить запятую между подлежащим и сказуемым.
Все предложения можно разделить на несколько типов в зависимости от грамматической основы.
По составу грамматической основы
По составу грамматической основы предложения бывают двусоставными или односоставными.
Двусоставные предложения — это те, в которых оба главных члена предложения в наличии, например:
- Кошка спит. Птички поют.
- Папа пошел на работу.
- На небе показалось солнце.
У односоставных предложений есть только один главный член — либо подлежащее, либо сказуемое. Примеры таких предложений:
- Смеркалось. Вечерело.
- Жара. Июль.
- Как хорошо!
По числу грамматических основ
Если в предложении одна грамматическая основа, оно называется простым. Примеры простых предложений:
- Девочка пошла гулять с собакой.
- Заяц ускакал в лес.
- На небе показалось солнце.
Если грамматических основ две или больше, то мы имеем дело со сложным предложением. Давайте превратим простые предложения из примера выше в сложные:
- Девочка пошла гулять с собакой, а ее брат остался дома.
- Заяц ускакал в лес, и охотники остались ни с чем.
- Наконец дождь закончился, и на небе показалось солнце.
По наличию второстепенных членов
В зависимости от того, есть ли в предложении второстепенные члены, оно может быть распространенным или нераспространенным.
Нераспространенными называют такие предложения, в которых есть только грамматическая основа и ничего больше. Например:
- Девочка гуляет.
- Заяц скачет.
- Дождь закончился.
В распространенных предложениях, кроме грамматической основы, есть еще второстепенные члены: дополнения, определения, обстоятельства. Давайте дополним примеры выше, чтобы предложения стали распространенными:
- Девочка гуляет с подружками.
- Заяц скачет по лужайке.
- К вечеру дождь закончился.
Изучайте русский язык в онлайн-школе Skysmart — с внимательными преподавателями и на интересных примерах из современных текстов.
Стили текста
Дорогие ребята, мы узнали много нового о тексте! Но Непоседкин нашел два текста и не может понять, почему они такие разные! Давайте поможем ему в этом разобраться.
Прочтите два текста одной тематики.
|
1. Зеленым ковром до самых небес простирается луг величавый. Он радует взор, он прекрасен и чист, чудеса природы завораживают. |
2. Луг – это участок земли с многолетними травянистыми растениями. Для него характерна увлажненная почва. |








Вопросы
- В чем отличия описания луга?
Ответ: в словах, в первом — много красивых описаний, во втором названы конкретные факты научными словами.
- Какое впечатление произвел каждый текст?
Ответ: первый текст вдохновляет, второй кажется скучным.
- Где можно увидеть описание луга в первом и во втором случае?
Ответ: 1 – в художественной книге; 2 – в энциклопедии, словаре, учебнике.
Ребята, все мы знаем, что есть разные книги: учебники, энциклопедии, художественные произведения. И в каждой из этих книг написаны тексты, но по-разному. Как мы увидели на примере, можно писать красивыми словами в рассказах и повестях. А вот в энциклопедиях мы встречаем только сухие факты, научные данные, сложные термины. Такое различие в русском языке называют стилями.
Всего нужно знать пять стилей текста 1. Научный (статьи в учебной литературе).
Глютен – разновидность белка, клейковина зерновых растений.2. Публицистический (используется в газетах, журналах, на радио и телевидении).
Россия – наша великая и могучая страна, держава, коих нет равных во всем белом свете!3. Художественный (рассказы, повести, поэмы, поэзия, романы).
Буря мглою небо кроет, вихри снежные крутя… 4. Официально-деловой (законы, документы).Прошу предоставить отпуск без содержания по семейным обстоятельствам.
- Разговорный (устное общение друг с другом).
— Привет, дружище, как делищи?
Сделаем вывод: все тексты можно разделить на пять стилей, в зависимости от сферы употребления. Нам нужно уметь отличать научный текст от разговорного и художественного.
Выполним задания, Непоседкину опять нужна помощь! Помогите ему, правильно расставить стили текста. Исправьте ошибки.
- Всем нужно учить русский язык. Он прекрасен и мелодичен. Таит в себе множество загадок. Изучив его, мы узнаём много нового, становимся грамотными людьми. Только зная русский язык, мы сможем правильно расставить знаки препинания.
Ребята, вы согласны с Васей?
Ответ: нет, в тексте мало научных фактов, терминов, много эмоций, это художественный стиль.
- Предложение в русском языке – это соединение нескольких связанных между собой слов. Оно должно быть завершено логически и интонационно. В конце предложения ставятся знаки завершения: точка, восклицательный или вопросительный знак.
Ответ: абсолютно верно, данный текст является научным.
Пунктуационное оформление перечней
В Примере 3 хорошо видно, что заголовки первого и второго уровней начинаются с заглавных букв,а заголовки последующих уровней – со строчных. Это происходит потому, что после римских и арабских (без скобок) цифр по правилам русского языка ставится точка, а после точки, как все мы помним с начальной школы, начинается новое предложение, которое пишется с заглавной буквы. После арабских цифр со скобками и строчных букв со скобками точки не ставится, поэтому последующий текст начинается с маленькой буквы. Последнее положение, кстати, относится и к тире, поскольку трудно представить себе сочетание тире с точкой после него.
Обратите внимание на знаки препинания в конце заголовков перечня, а также в конце слов и словосочетаний в его составе.
Если заголовок предполагает последующее членение текста, то в конце него ставится двоеточие, если же последующего членения не будет, ставится точка
Пример 5
![]()
Если части перечня состоят из простых словосочетаний или одного слова, они отделяются друг от друга запятыми (см. Пример 5). Если же части перечня усложнены (внутри них есть запятые), их лучше отделять точкой с запятой (см. Пример 6).
![]()
Наконец, если части перечня представляют собой отдельные предложения, они друг от друга отделяются точкой:
Пример 7
![]()
Иногда перечень оформляется таким образом, что его предваряет целое предложение (или несколько предложений). В этом случае в перечне используются лишь так называемые «низшие» уровни членения (строчные буквы со скобкой или тире), а точки в конце каждой части перечня не ставятся, т.к. в данном случае перечень представляет собой единое предложение:
Пример 8
![]()
Бывает, что в какие-либо части перечня, представляющие собой словосочетания, включается самостоятельное предложение, начинающееся с заглавной буквы. Независимо от того, что в конце предложения по правилам русского языка должна ставиться точка, каждый элемент списка будет отделяться от следующего точкой с запятой:
Порядок определения грамматической основы
Умение определять основы в предложениях — очень важный и полезный навык. От него зависит, правильно человек расставит знаки препинания в предложении или будет делать множество орфографических ошибок.
Чтобы сделать это, нужно внимательно прочитать текст выделить в каждом предложении основные слова
Важно помнить, что любое предложение может быть как односоставным, так и двусоставным
Определение основы в односоставных предложениях
Наибольшую трудность вызывает определение основы именно в подобных предложениях, то есть в тех, где есть либо подлежащее, либо сказуемое. Они бывают разных видов.
Если в составе основы присутствует только подлежащее, то оно классифицируется как Назывное (например, ). Если же в предложении только сказуемое, то в этой ситуации все намного сложнее. Подобные конструкции делятся на пять подвидов:
- Определённо-личные — те, в которых глагол стоит в форме первого или второго лица (к примеру, — в этом случае можно подставить местоимение первого лица — я, соответственно оно определенно-личное).
- Неопределенно-личные — те, в которых глагол стоит в форме третьего лица (например, ).
- Обобщенно-личные. Не имеют своей специфической формы выражения. Чаще всего к ним относятся поговорки, пословицы и различные другие виды народной мудрости (например, ).
- Безличные. В них сказуемое выражено глаголом в безличной форме. Очень часто они связаны с погодными явлениями (например, ).
- Инфинитивное. В подобных предложениях сказуемое выражено глаголом-инфинитивом. (например, , где «прогибаться» — сказуемое).
С такими предложениями надо работать по стандартной схеме. Первоначально найти объект, который совершает действие, а потом то, что он делает. Если тот или другой член предложения не получается найти, то вполне вероятно, что его там и нет изначально.
Двусоставные предложения: алгоритм определения грамматической основы
Это действие не должно вызывать трудностей. Все делается по описанной выше, стандартной схеме. Однако есть несколько ситуаций, когда определить основу предложения бывает очень затруднительно. В особенности вопросы вызывают сказуемые.
Сложные случаи в определении сказуемых
Зачастую проблемы с определением сказуемого возникают в ситуации, когда простое глагольное сказуемое выражено не одним словом. Напомним, что такое возможно в сочетании с употреблением вспомогательного глагола «быть» в личной форме, частиц — «пусть», «давай», «пускай», «давайте» и когда сказуемое представлено в виде фразеологизмов, которые могут быть заменены одним словом. Например:
В каждом из примеров мы имеем дело с простым глагольным сказуемым. О таких явлениях стоит помнить и не удивляться, когда они появляются в тексте.
Ошибка в определении типа сказуемого часто бывает связана с тем, что человек неверно определил часть речи (например, перепутал причастие и глагол). Поэтому в любой ситуации следует быть максимально внимательными и все перепроверять по несколько раз.
Цифры и ноты
Криптограммы с цифрами практически никогда не состоят из одних лишь цифр, как правило, они встречаются в комбинации с картинками, буквами, нотами и прочим. По сути, наличие цифр – это вспомогательный фактор, диктующий условия для разгадывания ребуса. Как разгадывать ребусы с цифрами:
- Если над изображением какого-либо предмета стоят цифры в разном порядке, это значит, что буквы изображенного слова читаются в указанном порядке.
- Если цифры в ребусе зачеркнуты, значит, из него нужно выкинуть те буквы, которые соответствуют зачеркнутым цифрам.
Ребусы с нотами могут показаться людям, не имеющим музыкального образования, сложными и требующими особых знаний для того, чтобы их решать. Отчасти они правы – в таких головоломках в большинстве случаев используют изображение нот, для обозначения соответствующих им слогов – «до», «ре», «ми» и т.д. И тогда придется вспомнить школьные уроки музыки, и определить, что за нота изображена в ребусе.
В некоторых, упрощенных случаях, изображение скрипичного ключа дает понять, что задействовано лишь слово «нота».
Сколько всего существует иероглифов?
Иероглиф в классическом письменном языке вэньянь 文言 означал, как правило, целое слово. В современном китайском языке слова большей частью состоят из одного-двух, реже трех и более иероглифов. Поэтому иероглифов существует очень много.
В 1994 году был издан словарь «Море китайских иероглифов» Чжунхуа цзыхай 中華字海, в котором насчитывается 85568 иероглифов! Правда, подавляющую их часть можно встретить лишь несколько раз в классических литературных произведениях. Обычные двуязычные словари насчитывают около 6-8 тысяч иероглифов, среди которых также попадается немало редких. Более полные толковые словари насчитывают около 10-20 тысячи знаков.
Считается, что для понимания 80% современного обычного китайского текста достаточно знать 500 наиболее частотных иероглифов, знание 1000 иероглифов дает понимание примерно 91% текста, а 2500 иероглифов – 99% текста. Для того, чтобы сдать экзамен для иностранцев на знание китайского языка высшего уровня HSK 6, нужно знать чуть меньше 3000 иероглифов. Для чтения специальной научной или классической литературы нужно понимать большее количество иероглифов.
Однако надо иметь ввиду, что даже если все иероглифы в тексте вам знакомы, вы далеко не всегда абсолютно точно поймете смысл написанного. Нужно знать еще и слова — различные словосочетания иероглифов. В китайском языке используется довольно много сокращений, когда устойчивые словосочетания из нескольких иероглифов сокращаются до более коротких.









Так, например, словосочетание «Пекинский университет» 北京大学 Běijīng dàxué сокращается до 北大 Běidà, что буквально означает «северный большой». Другая сложность китайского языка — это использование чэнъюй 成语 — идиом, состоящих, как правило, из четырех иероглифов. При буквальном переводе каждого из знаков смысл сказанного может оказаться непонятым. Существуют специальные словари чэнюев, а также сборники рассказов, где поясняется смысл наиболее известных идиом. Переводы чэнъюй можно найти и в словарях.
По теме: Что такое чэнъюй
В японском языке существует обязательный список иероглифов Дзёё кандзи 常用漢字, принятый Министерством образования Японии в качестве достаточного в повседневном употреблении. Он состоит из 2136 кандзи (иероглифов) и включает 1006 кёику кандзи, которые изучают школьники в 6-летней начальной школе и 1130 кандзи, которые учат в средней школе.
§ 8. Создание списков в HTML
В HTML списки создаются с помощью тегов и . В первом случае создается упорядоченный (нумерованный), во втором неупорядоченный (маркированный) списки. Каждый элемент списка выделяется тегом . Браузер отображает элементы списка с новой строки в виде столбца с отступом и маркерами. Вид маркера определяется атрибутом type.
В нумерованном списке маркеры (значения атрибута type) такие:
- 1 — нумерация арабскими цифрами (по умолчанию);
- A — большими латинскими буквами по алфавиту;
- a — маленькими латинскими буквами;
- I — большими римскими цифрами;
- i — маленькими римскими цифрами.
Например, HTML-код
Первый элемент.Второй элемент.Третий элемент.
браузер покажет так:
- Первый элемент.
- Второй элемент.
- Третий элемент.
В маркированном списке значения атрибута type такие:
- disc — закрашенный кружок (по-умолчанию);
- circle — незакрашенный кружок;
- square — закрашенный квадратик.
Например, HTML-код
Первый элемент.Второй элемент.Третий элемент.
в браузере выглядит так:
- Первый элемент.
- Второй элемент.
- Третий элемент.
Как и остальные теги HTML, списки можно вкладывать друг в друга. Получаются многоуровневые вложенные списки. Например, код:
Первый элемент. Второй элемент. Третий элемент. Четвёртый элемент. Пятый элемент.
браузер покажет так:
- Первый элемент.
-
- Второй элемент.
- Третий элемент.
- Четвёртый элемент.
- Пятый элемент.
Обозначение элементов списка
Предваряющее перечень предложение и элементы последующего списка (перечисляются после двоеточия) могут писаться в виде единой строки. Но в длинных и сложных списках гораздо удобнее располагать каждый элемент с новой строки. И тут у вас есть выбор: вы можете ограничиться использованием абзацного отступа (Пример 1) или же заменить его на цифру, букву или тире (Пример 2).
Пример 2
![]()
От глубины членения зависит выбор символов, которые будут предварять каждый элемент списка. При оформлении простых перечней можно использовать строчные («маленькие») буквы, арабские цифры или тире.
Гораздо сложнее обстоит дело с составными перечнями. Для большей наглядности сочетания различных символов в списках приведем пример оформления 4-уровневого перечня:
Пример 3
![]()
Из данного примера видно, что система нумерации рубрик выглядит следующим образом: заголовок первого уровня оформлен при помощи римской цифры, заголовки второго уровня – при помощи арабских цифр без скобок, заголовки третьего уровня – при помощи арабских цифр со скобками и, наконец, заголовки четвертого уровня оформлены с применением строчных букв со скобками. Если бы данный перечень предполагал еще один, пятый уровень, то его мы оформили бы при помощи тире.
Система нумерации частей составного перечня может состоять только из арабских цифр с точками.Тогда структура построения номера каждого элемента списка отражает его подчиненность по отношению к расположенным выше элементам (происходит наращивание цифровых показателей):
Пример 4
![]()
Если в конце списка стоит «и др.», «и т.д.» или «и т.п.», то такой текст не располагают на отдельной строке, а оставляют в конце предыдущего элемента списка (см. Примеры 3 и 4).
Как запомнить чтение иероглифов
Хотя в китайском языке большинство иероглифов относится к категории фоноидеограмм, тем не менее, иероглиф не содержит прямого указания на чтение, как фонетические языки. Еще одна трудность китайского языка заключается в широком распространении явления омофонии: из-за ограниченного количества слогов (немногим более 400), разные иероглифы могут читаться одинаково, что создает определенные трудности в понимании устной речи. Тем не менее, очень удобно запоминать целый ряд иероглифов, имеющих одинаковое чтение.
Подробнее: Омофоны в китайском языке и некоторые традиции, связанные с ними
На первых порах своего изучения китайского языка тон я обычно запоминала по какой-нибудь черте: горизонтальная черта в верхней части иероглифа означала первый тон, наклонная влево — второй тон, горизонтальная внизу — третий тон, наклонная или откидная вправо — четвертый тон. Хотя встречались иероглифы, где нужной черты не находилось.
Совершенно иная ситуация складывается в японском языке, где существует два вида чтения иероглифов: онное, пришедшее из китайского языка, и кунное, традиционное японское. Таким образом, один иероглиф может иметь до 5 и более различных чтений! В разных словосочетаниях иероглифы могут читаться по-разному.
Например, в японском языке слова «вчера» 昨日 и «завтра» 明日, имеющие в своем составе одинаковый знак 日 (день, солнце), читаются абсолютно по-разному: kino: и ashita соответственно. В словосочетании «каждый день», «ежедневно» 毎日 будет читаться mainichi, «третье число», «три дня» 三日- mikka. Хотя, по идее, все четыре слова должны были бы оканчиваться одинаково.
Именно поэтому единственный действенный способ и в китайском, и в японском языке запомнить чтение иероглифов — это зубрежка: многократно проговаривать их про себя и вслух, пытаться запомнить мелодику. В китайском языке это сделать, на мой взгляд, проще в силу наличия фоноидеограмм и общей повторяемости слогов, в японском — чуть сложнее.
Обзор стилей речи, как определить стиль текста
Научный — применяется для написания диссертаций, монографий, статей и пр. Текст научного стиля легко определить. Для него характерно:
- наличие множества незнакомой терминологии;
- громоздких предложений;
- объемных абзацев (на пол страницы);
- применение массы существительных и совсем немного глаголов;
- безличность, т. е. вместо «я» — «мы».
Деловой стиль текста и официальный стиль текста совмещен в один — официально-деловой. И не зря, ведь они очень близки. Сотрудники коммерческих и государственных учреждений знают об этом не понаслышке. Все официальные документы, начиная с законов и заканчивая деловыми записками, пишутся в этом стиле.
Это язык отчетов, инструкций, накладных и т. д. Он характеризуется: отглагольными существительными, прямым порядком слов, длинными предложениями, жесткой логикой, широким использованием языковых клише и штампов, предельной точностью в изложении информации в ущерб удобства восприятия и легкости чтения.
Публицистический — встречается в журналах, газетах, статьях в общественных блогах, новостных сайтах и других СМИ. Его особенность — твердая нацеленность на результат: подача информации, которая будет воздействовать на мировоззрение большого числа людей и влиять на их отношение к общественным делам и проблемам.
Текст публицистического стиля часто состоит из отвлеченных слов и понятий, имеющих большое политическое, нравственное или общественное значение. Например, такие слова и фразы как прогресс, свобода слова, патриотизм, развитие и мн. др. Также ему свойственны: образность, логичная подача информации, призывы к действию, оценки и насыщенность эмоциями.
Художественный — богат на экспрессивно-эмоциональную лексику. Опознать художественный стиль текста просто: множество метафор и сравнений, наличие оттеночных слов (жаргонных, устаревших, ругательных), необычная авторская позиция, легкие для восприятия предложения.
Разговорный — встречается в повседневном живом общении. При желании автора установить более тесный контакт со своими читателями, этот стиль используется в письменной речи. Он часто встречается в продающих текстах, заметках соцсетей, личных заметках в блоге и др.
Текст разговорного стиля отличается ярко выраженной экспрессией, красочностью, живой речью, высокой субъективностью и оценочностью, неполными предложениями, разговорными и просторечными словами и оборотами, повторами. А иногда даже ненормативной лексикой.
Как определить размер стихотворения
Метод 1. Скандирование
Допустим, требуется определить размер этого текста:
Самый простой способ определить стихотворный размер этого отрывка — проскандировать его как детскую считалку или кричалку на стадионе. Нужно абстрагироваться от расположения ударений в каждом слове и постараться поймать общий ритм стиха. Ударные слоги можно выстукивать рукой по столу или притопывать в такт.
как-СЕ-рдцу-ВЫ-ска-ЗАТЬ-се-БЯдру-ГО-му-КАК-по-НЯТЬ-те-БЯ
Выстукивая ритм, нетрудно заметить, что акценты приходятся на каждый второй слог. Следовательно, перед нами двусложный размер. А поскольку нечётные слоги безударные — это ямб.
Метод 2. «Ваня»
Этот метод придуман стиховедом А.А. Илюшиным. Определить классические размеры стихов можно, соотнося его с разными формами имени Иван:
Ваня — хорей:«Буря мглою небо кроет» (А.С. Пушкин)Ваня-Ваня-Ваня-Ваня
Иван — ямб:«И буду век ему верна» (А.С. Пушкин)Иван-Иван-Иван-Иван
Ванечка — дактиль:«Ранними летними росами» (А.А. Блок)Ванечка-Ванечка-Ванечка
Ванюша — амфибрахий:«Однажды в студёную зимнюю пору» (Н.А. Некрасов)Ванюша-Ванюша-Ванюша-Ванюша
Иоанн — анапест:«Я тебе принесу два кармана стрижей с маяка» (Н. Подвальный)Иоанн-Иоанн-Иоанн-Иоанн-Иоанн
Метод 3. Графический
Этот метод требует больше всего времени, зато он самый наглядный и точный.
Для наиболее точного определения стихотворного размера рекомендуется брать отрывки не менее 6-8 строк.
Допустим, нужно определить размер следующих стихотворных строк:
Распечатаем или перепишем текст на бумагу, после чего карандашом разделим его на слоги, расставим ударения и нарисуем схему:
Я| ве|рну|лся| в мой| го|род|, зна|ко|мый| до| слёз|,—U—UU—UU—UU—
До| про|жи|лок|, до| де|тских| при|пу|хлых| же|лёз|.UU—UU—UU—UU—
Ты| ве|рнул|ся| сю|да|, так| гло|тай| же| ско|рей|—U—UU—UU—UU—
Ры|бий| жир| ле|ни|нгра|дских| ре|чных| фо|на|рей|.—U—UU—UU—UU—
Внимательно посмотрим на схему. В большинстве случаев ударные слоги разделяются двумя безударными. Значит, перед нами трёхсложный размер. Попробуем разделить его на стопы по три слога:










—U—|UU—|UU—|UU—| UU—|UU—|UU—|UU—|—U—|UU—|UU—|UU—|—U—|UU—|UU—|UU—|
Большинство ударений в стопах падает на третий слог. Следовательно, это анапест.
List Comprehensions как обработчик списков
В языке Python есть две очень мощные функции для работы с коллекциями: map и filter. Они позволяют использовать функциональный стиль программирования, не прибегая к помощи циклов, для работы с такими типами как list, tuple, set, dict и т.п. Списковое включение позволяет обойтись без этих функций. Приведем несколько примеров для того, чтобы понять о чем идет речь.
Пример с заменой функции map.
Пусть у нас есть список и нужно получить на базе него новый, который содержит элементы первого, возведенные в квадрат. Решим эту задачу с использованием циклов:
>>> a =
>>> b = []
>>> for i in a:
b.append(i**2)
>>> print('a = {}\nb = {}'.format(a, b))
a =
b =
Та же задача, решенная с использованием map, будет выглядеть так:
>>> a =
>>> b = list(map(lambda x: x**2, a))
>>> print('a = {}\nb = {}'.format(a, b))
a =
b =
В данном случае применена lambda-функция, о том, что это такое и как ее использовать можете прочитать здесь.
Через списковое включение эта задача будет решена так:
>>> a =
>>> b =
>>> print('a = {}\nb = {}'.format(a, b))
a =
b =
Пример с заменой функции filter.
Построим на базе существующего списка новый, состоящий только из четных чисел:
>>> a =
>>> b = []
>>> for i in a:
if i%2 == 0:
b.append(i)
>>> print('a = {}\nb = {}'.format(a, b))
a =
b =
Решим эту задачу с использованием filter
>>> a =
>>> b = list(filter(lambda x: x % 2 == 0, a))
>>> print('a = {}\nb = {}'.format(a, b))
a =
b =
Решение через списковое включение:
>>> a =
>>> b =
>>> print('a = {}\nb = {}'.format(a, b))
a =
b =
§ 9. Заключение
Рассказ о том, что нужно для форматирования текста в HTML, был бы не полным без упоминания о спецсимволах. Спецсимволы — это символы, которых либо нет на клавиатуре, либо те, которые браузер принимает за управляющий символ и преобразует в код. Полный список этих символов ты найдешь здесь Спецсимволы HTML. Кроме того, самые главные знания для форматирования текста — это правила грамматики русского языка. Грамотно написанный текст уже наполовину отформатирован.
Ну и напоследок, для закрепления всего вышеизложенного, в качестве самостоятельной работы, изучи вот этот HTML-код:
Н
и попробуй сам понять, что означают эти теги и их атрибуты, а также, где на этой странице мог бы использоваться этот код HTML.
На этом рассказ о тегах HTML для форматирования текста объявляется законченным. Раздел получился довольно большим. Не пытайся выучить все новые теги и атрибуты наизусть, всё равно не получится. Они сами постепенно запомнятся во время работы над созданием сайта.
В следующем разделе поговорим о том, как вставить картинку в html-страницу.
⇓
Поделись ссылкой на Seoded.ru с друзьями, знакомыми и собеседниками в соцсетях и на форумах! А сам сайт добавь в закладки! Так победим.
Поделиться ссылкой на эту страницу в:



